序
Kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[3]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库)。
Kafka架构
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为聚类部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
Kafka架构的主要术语包括Topic、Record和Broker。Topic由Record组成,Record持有不同的信息,而Broker则负责复制消息。Kafka有四个主要API:
- 生产者API:支持应用程序发布Record流。
- 消费者API:支持应用程序订阅Topic和处理Record流。
- Stream API:将输入流转换为输出流,并产生结果。
- Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。
环境依赖
基础使用
假设Kafka环境和Zookeeper环境都没有
1. 下载并解压
> tar -xzf kafka_2.13-2.8.0.tgz
> mv kafka_2.13-2.8.0.tgz /usr/local/kafka
> cd /usr/local/kafka
2. 启动服务
kafka的启动依赖于Java环境,所以在使用Kakfa之前,记得配置Java8+的环境
> bin/zookeeper-server-start.sh config/zookeeper.properties
打开另一个命令终端启动kafka服务:
## 用于后台启动
> bin/kafka-server-start.sh config/server.properties &
一旦所有服务成功启动,那Kafka已经可以使用了。
3. 创建一个主题
创建一个名为“test”的Topic,只有一个分区和一个备份:
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
创建好之后,可以通过运行以下命令,查看已创建的topic信息:
> bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
Topic:quickstart-events PartitionCount:1 ReplicationFactor:1 Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
4. 发送消息
Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
运行 producer(生产者),然后在控制台输入几条消息到服务器。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
hello world
what's your name
5. 消费消息
Kafka也提供了一个消费消息的命令行工具,将存储的信息输出出来,新打开一个命令控制台,输入:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
hello world
what's your name
注意,若是在服务器开启kafka服务,然后本地消费生产的消息,需要在kafka中的 config/service.properties 中修改配置(注意开启服务器对应的端口)
advertised.listeners=PLAINTEXT://your ip : your port
6. 使用 Kafka Connect 来 导入/导出 数据
可能现有的系统中拥有大量的数据,如关系型数据库或传统的消息传递系统,以及许多已经使用这些系统的应用程序。Kafka Connect允许你不断地从外部系统提取数据到Kafka,反之亦然。用Kafka整合现有的系统是非常容易的。为了使这个过程更加容易,有数百个这样的连接器现成可用。
7. 使用Kafka Stream来处理数据
一旦我们的数据存储在Kafka中,就可以用Kafka Streams客户端库来处理这些数据,该库适用于Java/Scala。它允许你实现自己的实时应用程序和微服务,其中输入和/或输出数据存储在Kafka主题中。Kafka Streams将在客户端编写和部署标准Java和Scala应用程序的简单性与Kafka服务器端集群技术的优势相结合,使这些应用程序具有可扩展性、弹性、容错性和分布式。该库支持精确的一次性处理、有状态操作和聚合、窗口化、连接、基于事件时间的处理等等。
一个初步的体验,实现一个流行的WordCount算法的:
KStream<String, String> textLines = builder.stream("quickstart-events");
KTable<String, Long> wordCounts = textLines
.flatMapValues(line -> Arrays.asList(line.toLowerCase().split(" ")))
.groupBy((keyIgnored, word) -> word)
.count();
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
以系统服务方式启动kafka
创建 /usr/lib/systemd/system/zookeeper.service 并写入
[Unit]
Requires=network.target
After=network.target
[Service]
Type=simple
Environment="PATH=/opt/jdk-11.0.12/bin:/opt/jdk-11.0.12/jre/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
LimitNOFILE=1048576
ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh
Restart=Always
[Install]
WantedBy=multi-user.target
创建 /usr/lib/systemd/system/kafka.service 并写入
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
Environment="PATH=/opt/jdk-11.0.12/bin:/opt/jdk-11.0.12/jre/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
LimitNOFILE=1048576
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=Always
[Install]
WantedBy=multi-user.target
注意:示例的kafka安装地址在 /usr/local/kafka
因为系统服务不会直接读取我们配置在/etc/profile或者bash_profile中的环境变量,所以Environment一定要记得配置。
## 查看当前环境变量
export $PATH
启动服务
重载系统服务并启动
systemctl daemon-reload
systemctl enable zookeeper && systemctl enable kafka
systemctl start zookeeper && systemctl start kafka
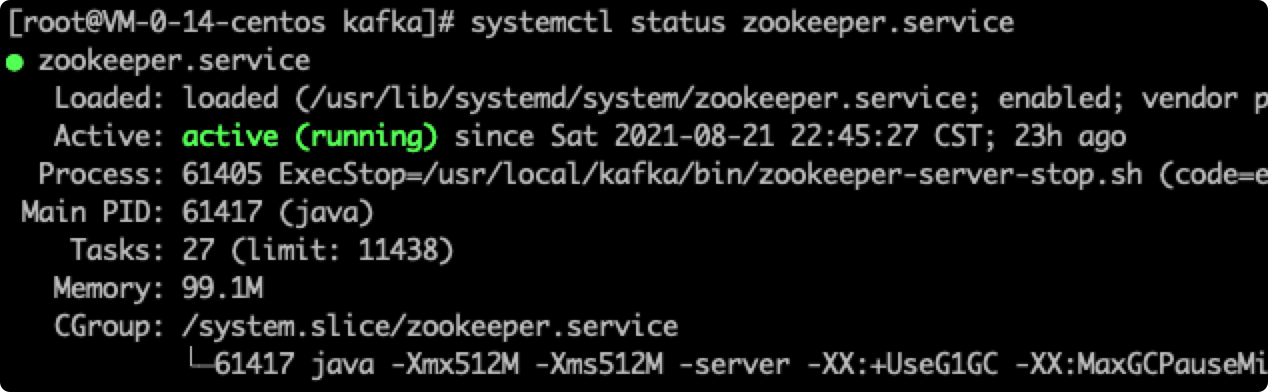
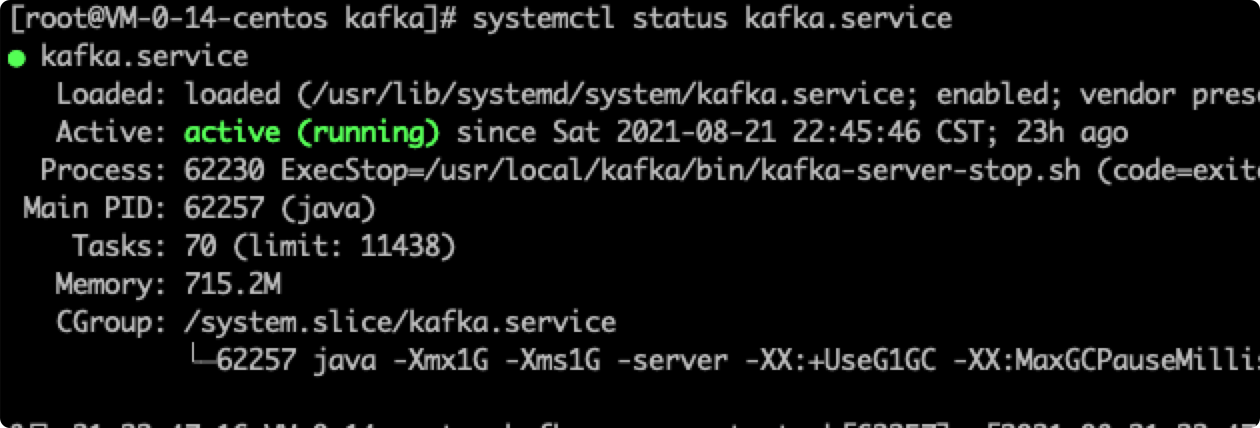
systemctl status zookeeper && systemctl status kafka